ai手机ai pc井喷在即 高通在加速布局以赋能生态繁荣 -2024欧洲杯正规平台
摘要:ai产品开发者需要先行一步,早一些让用户体验自己的产品,和用户建立连接,培养粘性,从而在竞争中占得先机。
2024注定是ai行业热闹非凡的一年。虽然刚刚进入3月份,但是关于ai的新闻已经多次占据了头条。就在上个月,openai发布了文字生成视频的大模型sora,其逼真的效果直接清空了在这个细分赛道苦苦耕耘的创业者。几天后,英伟达市值站上2万亿美元,成为了历史上最快实现从1万亿到2万亿美元市值的企业。正所谓“当你发现金矿,最好的生意不是挖矿而是卖铲子”,英伟达成为了ai时代“军备竞赛”的最大赢家。
就在大家感叹“世界上只有两种ai,一种叫openai,一种叫其他ai”的时候,沉寂了许久的anthropic放出王炸,这家由openai前研究副总裁创立的公司,发布了最新的claude3模型,各项指标已经全面超越了gpt4。
ai行业的风起云涌,也昭示了这个行业还处在一个初级阶段。技术迭代太快,暂时领先的企业可能在一夜之间就被新技术颠覆。一些眼花缭乱的新技术,虽然已经问世,但迟迟不公开或者没有部署。比如上文提到的sora,截至发文,还没有正式向公众开放。
生成式ai的研发和本地部署之间存在鸿沟。目前,大众使用的生成式ai产品往往是部署在云端而在本地访问(比如chatgpt网页),但这无法满足所有需求,并且会产生一些隐患。
首先,随着大模型越来越复杂,云端和本地之间的传输在有限带宽下变得捉襟见肘,比如一架波音787飞机每秒钟产生5g的数据,如果上传到云端、计算、输出结果再返回,飞机可能已经飞出去几公里了(按照800公里/小时估算)。如果在飞机上使用ai功能但是在云端部署,这样的传输速度是无法满足要求的。
此外,一些用户敏感数据、隐私数据,是否一定要上云?显然放在本地比云端更让用户放心。
不论生成式ai多么强大,如何部署到本地始终是一个无法绕开的问题。这是行业发展的趋势,虽然目前面临一些困难。
困难在于,如何把“大模型”装入“小设备”。注意,这里的“大小”是相对而言的。云端计算的背后可能是一个占地几万平方米的计算中心,而本地部署却要让生成式ai在你的手机上跑起来。手机没有液氮冷却,也没有无穷无尽的电力,该如何部署ai呢?
异构计算,一种可能的2024欧洲杯正规平台的解决方案?
高通的异构计算ai引擎(以下皆称作高通ai引擎)为行业提供了一种可行的2024欧洲杯正规平台的解决方案。即通过cpu、gpu、npu以及高通传感器中枢和内存子系统的协作,实现了ai部署和大幅度提升ai体验的目的。

图:专门的工业设计让不同计算单元更紧凑 来源:高通
不同类型的处理器所擅长的工作不同,异构计算的原理就是让“专业的人做专业的事”。cpu擅长顺序控制,适用于需要低延时的应用场景,同时,一些较小的传统模型如卷积神经网络模型(cnn),或一些特定的大语言模型(llm),cpu处理起来也能得心应手。而gpu更擅长面向高精度格式的并行处理,比如对画质要求非常高的视频、游戏。
cpu和gpu出镜率很高,大众已经相当熟悉,而npu相对而言更像一种新技术。npu即神经网络处理器,专门为实现低功耗、加速ai推理而打造。当我们在持续使用ai时,需要以低功耗稳定输出高峰值性能,npu就可以发挥最大优势。
举个例子,当用户在玩一款重负载的游戏,此时gpu会被完全占用,或者用户在浏览多个网页,cpu又被完全占用。此时,npu作为真正的ai专用引擎就会负担起和ai有关的计算,保证用户的ai体验流畅。
总结起来说就是,cpu和gpu是通用处理器,为灵活性而设计,易于编程,本职工作是负责操作系统、游戏和其他应用。npu则为ai而生,ai是它的本职工作,通过牺牲部分易编程特性而实现了更高的峰值性能和能效,一路为用户的ai体验护航。
当我们把 cpu、gpu、npu 以及高通传感器中枢和内存子系统集成在一起,就是异构计算架构。
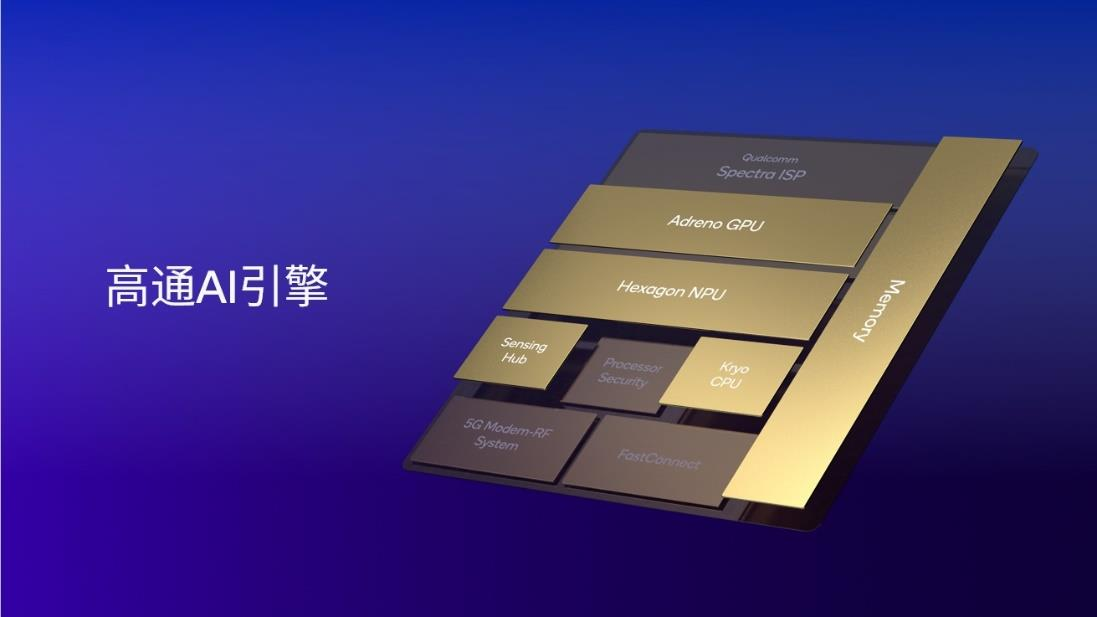
图:高通ai引擎包括hexagon npu、adreno gpu、高通oryon或 kryo cpu、高通传感器中枢和内存子系统 来源:高通
高通ai引擎整合了高通 oryon 或 kryo cpu、 adreno gpu 、 hexagon npu 以及高通传感器中枢和内存子系统。hexagon npu作为其中的核心组件,经过多年的升级迭代,目前已达到业界领先的ai处理水平。以手机平台为例,集成高通 ai 引擎的第三代骁龙 8 支持行业领先的lpddr5x内存,频率高达4.8ghz,使其能够以非常高速的芯片内存读取速度运行大型语言模型,如百川、llama 2等,从而实现非常快的token生成速率,为用户带来全新的体验。
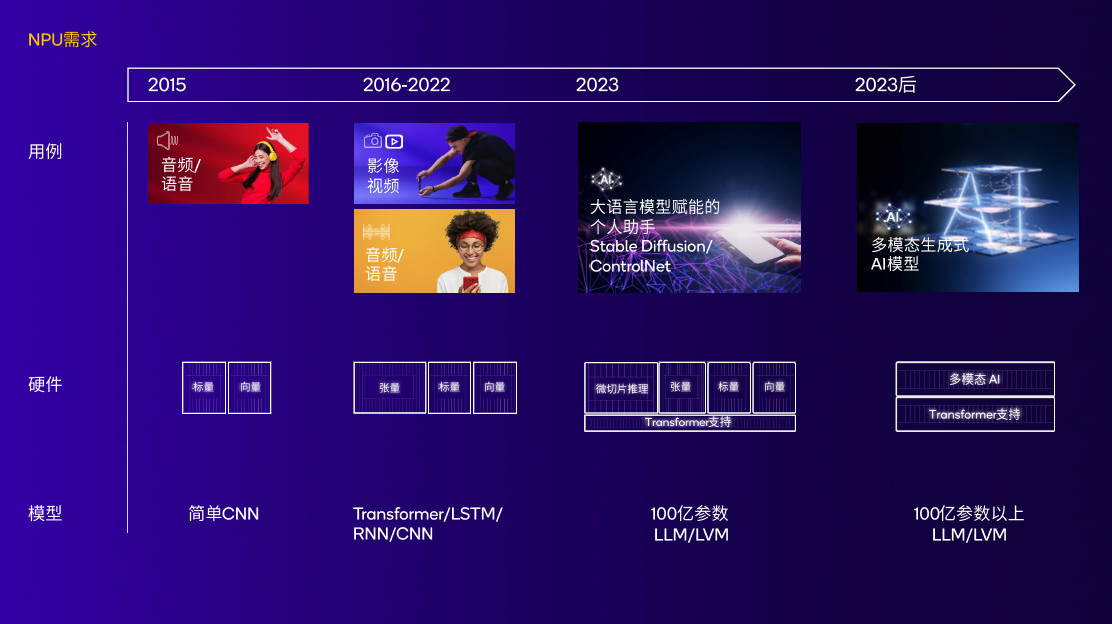
图:npu随着不断变化的ai用例和模型持续演进,实现高性能低功耗 来源:高通
高通对npu的研究,并不是近几年才开始的。如果要追溯hexagon npu的起源,要回到2007年,也就是生成式ai走入公众视野的15年前。高通发布的首款hexagon dsp在骁龙平台上亮相,dsp控制和标量架构成为了高通未来多代npu的基础。
8年后,也就是2015年,骁龙820处理器集成了首个高通ai引擎;
2018年,高通在骁龙855中为hexagon npu增加了张量加速器;
2019年,高通在骁龙865上扩展了终端侧ai用例,包括ai成像、ai视频、ai语音等功能;
2020年,hexagon npu迎来变革型架构更新。标量、向量、张量加速器融合,这为高通未来的npu架构奠定了基础;
2022年,第二代骁龙8中的hexagon npu引入了一系列重大技术提升。微切片技术提升了内存效率,功耗降低继续降低并且实现了4.35倍的ai性能提升。
2023年10月25日,高通正式发布第三代骁龙8。作为高通技术公司首个专为生成式ai而精心打造的移动平台,其集成的hexagon npu是目前高通面向生成式ai最新、也是最好的设计。
由于高通为ai开发者和下游厂商提供的是全套2024欧洲杯正规平台的解决方案(这部分内容会在第三部分详细叙述),并非单独提供芯片或者某个软件应用。这意味着在硬件设计上和优化上,高通可以通盘考虑,找出目前ai开发的瓶颈,做有针对性地提升。
比如,为何要特别在意内存带宽这个技术点?当我们把视角从芯片上升到ai大模型开发,就会发现内存带宽是大语言模型token生成的瓶颈。第三代骁龙8的npu架构之所以能帮助加速开发ai大模型,原因之一便在于专门提升了内存带宽的效率。
这种效率的提升主要受益于两项技术的应用。
第一是微切片推理。通过将神经网络分割成多个独立执行的微切片,消除了高达10余层的内存占用,此举最大化利用了hexagon npu中的标量、向量和张量加速器并降低功耗。第二是本地4位整数(int4)运算。它能将int4层和神经网络和张量加速吞吐量提高一倍,同时提升了内存带宽效率。
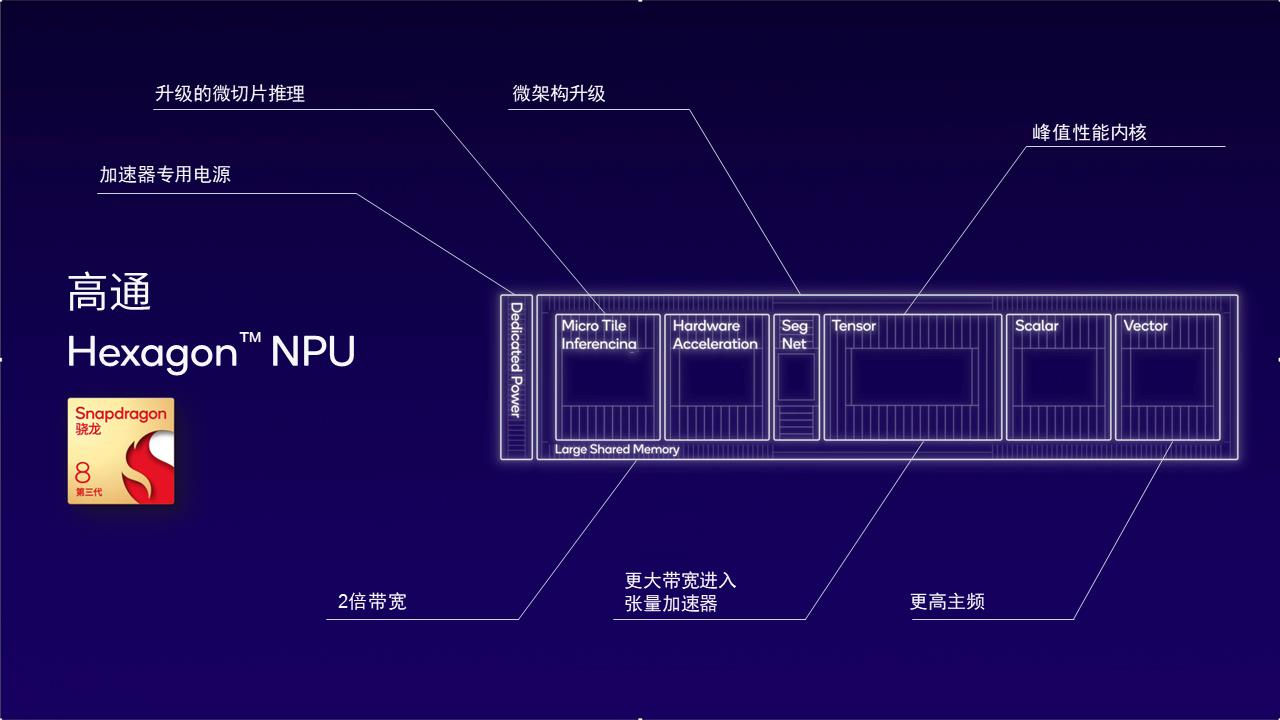
图:第三代骁龙8的hexagon npu以低功耗实现更佳的ai性能
2月26日,世界移动通信大会(mwc 2024)在巴塞罗那拉开帷幕。基于骁龙x elite,高通向全世界展示了全球首个在终端侧运行的超过70亿参数的大型多模态语言模型(lmm)。该模型可接收文本和音频输入(如音乐、交通环境音频等),并基于音频内容生成多轮对话。
所以,在集成了hexagon npu的移动终端上,会有怎样的ai体验?以及它是如何做到的?高通详细拆解了一个案例。
借助移动终端的ai旅行助手,用户可以直接对模型提出规划旅游行程的需求。ai助手可以立刻给到航班行程建议,并且通过语音对话调整输出结果,最后通过skyscanner插件创建完整航班日程。
这种一步到位的体验是如何实现的?
第一步,用户的语音通过自动语音识别(asr)模型whisper转化成文本。该模型有2.4亿个参数,主要在高通传感器中枢上运行;
第二步,利用llama 2或百川大语言模型基于文本内容生成文本回复,这一模型在hexagon npu上运行;
第三步,通过在cpu上运行的开源tts(text to speech)模型将文本转化为语音;
最后一步,通过调制解调器技术进行网络连接,使用skyscanner插件完成订票操作。
行业井喷前夕,开发者需要抢占先机
使用不同的工具测试骁龙和高通平台的ai性能表现,可以发现其得分比同类竞品高出几倍。从鲁大师aimark v4.3基准测试结果来看,第三代骁龙8的总分相较竞品b高出5.7倍,而相较竞品c高出7.9倍。
在安兔兔aitutu基准测试中,第三代骁龙8的总分比竞品b高出6.3倍。针对mlcommon mlperf推理的不同子项,包括图像分类、语言理解以及超级分辨率等,也进行了详尽的比较。
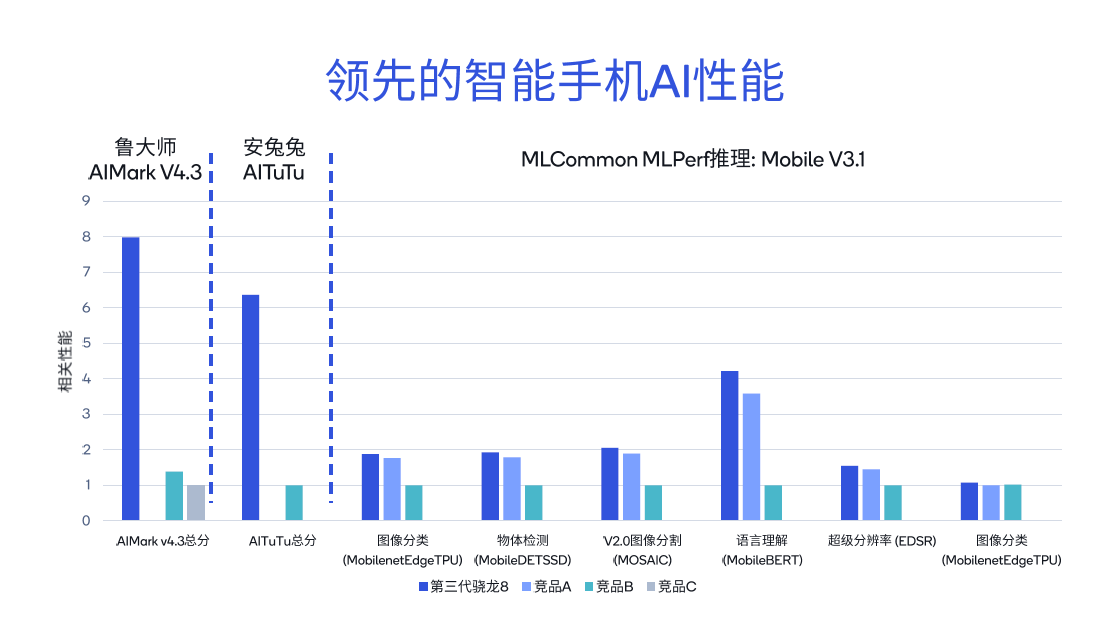
进一步对比骁龙x elite与其他x86架构竞品,在resnet-50、deeplabv3等测试中,骁龙x elite表现出明显的领先地位,其基准测试总分分别是x86架构竞品a的3.4倍和竞品b的8.6倍。因此,在pc端,无论是运行microsoft copilot,还是进行文档摘要、文档撰写等生成式ai应用,体验都十分流畅。
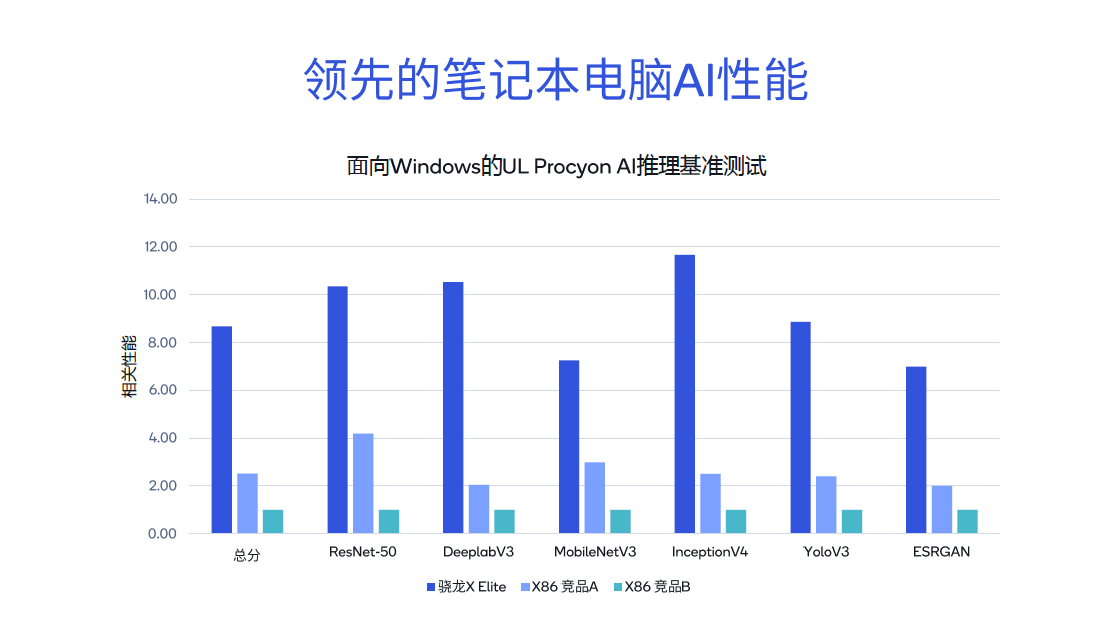
领先的ai性能不全是高通ai引擎的功劳,确切的说,高通对ai厂商的赋能是全方位的。
首先是高通ai引擎。它包括hexagon npu、adreno gpu、高通oryon cpu(pc平台)、高通传感器中枢和内存子系统。专门的工业设计、不同部件之间良好的协同,这款异构计算架构为终端侧产品提供了低功耗、高能效的开发平台。
基于先进的硬件,高通又推出了ai软件栈(高通ai stack)。这款产品的诞生是为了解决ai开发中的顽疾——同一个功能,针对不同平台要多次开发,重复劳动。ai stack支持目前所有的主流ai框架,oem厂商和开发者可以在平台上创建、优化和部署ai应用,并且能实现“一次开发,全平台部署”,大大减少了研发人员的重复劳动。

图:高通ai软件栈帮助开发者“一次开发,全平台部署” 来源:高通
此外,还有高通在mwc2024上刚刚发布的ai hub。ai hub是一个包含了近80个ai模型的模型库,其中既有生成式ai模型,也有传统ai模型,还包括图像识别或面部识别模型,百川、stable diffusion、whisper等模型。开发者可以从ai hub中选取想要使用的模型生成二进制插件,做到ai 开发的“即插即用”。

综合来说,如果纵向看深度,高通在硬件(ai引擎)、软件(ai stack)和素材库(ai hub)三个维度全面加速厂商的ai开发进度。横向看覆盖广度,高通的产品已经覆盖了几乎所有的终端侧设备(第三代骁龙8支持手机等终端,x elite赋能ai pc产品)。
ai应用处于井喷前的酝酿期。
在教育领域,ai能针对学生的学习能力和进度制定个性化的教学方案;在医学领域, ai可以用来发掘全新的抗生素类型;在养老方面,未来在一些社会老龄化问题比较严重的地区,可以利用ai终端收集老年人家中的所有个人数据,从而帮助预防紧急医疗事故。
之所以叫“井喷前”,正是因为还没有大规模部署。另一方面,ai应用,作为最容易让用户产生粘性的产品之一,具有很强的先发优势效应。
ai产品开发者需要先行一步,早一些让用户体验自己的产品,和用户建立连接,培养粘性,从而在竞争中占得先机。
(文章转载自deeptech深科技)
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
图片
精彩推送
- 普融花:人工智能的发展前景有哪些
- 龙年龙抬头丨龙牌集团、北新涂料甲辰龙年营销峰会圆满举行
- ai手机ai pc井喷在即 高通在加速布局以赋能生态繁荣
- 路虎携手广州总裁商会共襄盛举总裁闪电π队特别vip专场圆满落幕
- 美力绽放!新日独家冠名2024无锡太湖女子半马「新」势盎然
- 恒昌公益五“度”融合暖人心 五载同行赴未来
- 起势扬帆2024 东风汽车提速冲刺“新”征程
- 胡艳力对话李志林:简一剑指百年品牌的底气从何而来?
- 建设银行私人银行“财富守攻传”,2024全新呈现
- 加快发展新质生产力 东风奏响高质量发展“奋进曲”
- 诠释科学美肤力 麦吉丽重新定义“素颜美学”
- 荣获律新社《律所卓越品牌影响力指南(2023)》两大奖项,在明律所凭何?
- 全国人大代表刘宏志:推动数字乡村建设、激发乡村振兴“数智力量”
- 什么是原液?原液、精华液、肌底液有什么区别?
- 汉马科技2月产销稳步增长,持续提振市场信心
- 全国人大代表刘宏志:数字化建设加速 为乡村振兴提质增“智”
- 健合集团更懂新生代妈妈需求,联合零售龙头企业赋能终端渠道
- 春华秋实二十载 inter airport china 20年见证机场业之腾飞
- 只要get这几大要素,买电动车不踩雷,轻松拿下心动好车!
- 普融花:ai人工智能会带来哪些改变
- 瑞兽送福运,山海有相逢!交通银行标准信用卡国韵系列新年衔福而至
- id planet web 3.0 ceo 探讨《酷粒神 cool gods》游戏及id planet 第1层 evm公链的革命性
- 闲鱼「富」苏季,打赢年轻人节后翻身「账」
- 屈臣氏健康跑登陆花城 高燃开启健康活力新一年
- 喜迎元宵·情满长德 | 2024辞旧迎新送元宵活动圆满结束
- 成功占领“天下贵州人”盛典品牌c位,茅恒酒是谁?
- 暖心护航春运旅途 东风汽车彰显央企担当
- 共建汽车智能新生态的“遥遥领先” 东风汽车揭晓硬派越野新篇章
- “天下贵州人”春天之约,茅恒来了,贵州酱酒再添骨干力量
- 龙年春节 华熙live·五棵松活动丰富多彩 客流销售双增
- 2024龙年的“第一嗨”给了罐子?妈妈和宝宝情绪价值都拉了个满…
- 浓浓年味中,撒贝宁演绎名门之“秀”
- 看别人公司的春节福利,我简直太羡慕了!
- 《彩妆带货王》成团夜,十大美妆主播成功登上王座!
- 远程星瀚h醇氢电动重卡3000公里护送卫星,再度验证醇氢技术可靠性
- 保亭举办第二届“红毛丹”杯企业家高尔夫邀请赛
- 东风汽车1月销量喜迎“开门红”
- 修丽可登顶全球医美峰会——第25届英卡思国际大会,整全护肤最新成果亮相国际舞台
- 巨量云图游戏版,挖掘机会人群,引爆游戏新增量
- 丰田金融服务多举措推动汽车消费稳速增长
- 再获食品界“奥斯卡”认可 辉山奶粉三款产品摘星iti国际美味奖
- cpb肌肤之钥「东方美学艺术周末」活动盛耀启幕
- 竟然是ta们!金领冠突然官宣,群星高调亮相,早就看出不对劲了!
- 承载乡味的精神力量,看完这个视频就懂了!
- 英语听说必备三大核心力,阿尔法蛋ai听说宝d1一站配齐!
- web3游戏巨头id planet成功融资3500万美元,epic ecosmo和美国林氏集团牵头投资
- 金茗教育志愿填报,助力高考学子圆梦
- 斩获多项大奖 东风汽车闪耀第四届《中国汽车风云盛典》
- 最近的年轻人,开始流行当“过年主理人”
- line friends全新品牌旗舰店焕新回归,正式入驻上海美罗城
- 把握养生觉醒潮,和府捞面新品“硬核”进化
- 哈银消费金融:金融科技的积极探索者,合规发展的坚定践行者
- 陈昊:科技创新塑优势,共绘发展同心圆
- 非遗也很潮!又梨×fion带你感受传统艺术与潮玩的碰撞花火
- 弗兰德传动发布新款多级齿轮箱产品 驱动无限可能
- 实干笃行,高质发展——北京在明律师事务所2023年度表彰大会暨2024年迎新晚会圆满举行
- 酪神世家郭本恒携手吴少勋、魏立华、胡栋龙,开拓中国乳业奶酪新锚地
- 乘风破浪 迎新集结|升阳光吹响2024“户用冲锋号”
- 中国一乡一品“酉阳 800”抖音“酉”好物电商消费节在渝启动
- 王府井集团2024新年消费季 力促新春“开门红”
- 头部ip差异化、自制ip精品化,优酷少儿的内容孵化方法论
- 辉山奶粉持续加码品牌建设,2023品牌声量同比增长91%
- 2024第二届海南国际热带食材供应链博览会 正式开启招商招展
- 从屈臣氏立体零售生态,洞见美妆零售行业未来机遇
- 论电动车界的气质担当,还得是新日阿尔法
- 2024【信念·信心·希望】博研全球同学年会成功举办
- 抓住年轻人的情绪dna,屈臣氏破局年轻化
- 泰康尊享世家(旗舰版),实现跨周期的财富管理
- 借力金融业务转型深耕财富管理 开科唯识拟冲刺创业板ipo
- 郑州积云教育:全方位品质教学,搭建大学生毕业就业立交桥
- 新日再造爆款车型,揭秘阿尔法“弯道车王”的秘诀
- lg在ces 2024展出新款styler,开创衣物护理新领域
- 新形态 新发展 | gani简一2024年持续增长战略峰会隆重举办
- 为营销碎片化焦虑的品牌,在屈臣氏找到了答案
- 60%的居民缺少养老筹资规划:长寿时代已至,认知亟待提升
- 个性化体验,美妆零售的下一个“卷”点?
- 产线效率≥60ppm!海目星首条圆柱装配线成功出货!
- 科技创新走在前 东风汽车入选国家重点产品、工艺“一条龙”应用示范
- 中荷人寿荣获金龙奖"年度最佳合资寿险公司"奖项
- 零售混沌期,屈臣氏举起了融合的“火把”
- 用年轻人心动的语言,重启一座城
- 时尚产业变革者:urban revivo如何抓住机遇,实现品牌逆袭
- 青花郎杯百万大奖品酒大赛庄园总决赛报名通道已开启
- 新年新cp,时代猛士助推科技东风加速向“新”
- 回眸2023,“中国视谷”这一年……
- 易律易顺法顾团队:专业、高效、规范成为法律顾问首选
- 服务转型,锚定用户价值——中国建筑陶瓷行业高质量发展典型示范案例
- 美的空调冠名ip“炙热的他”决出五强,粉丝推选淘宝优质主播
- 这家企业为什么让罗振宇眼前一亮?
- 同名不同效!白云山小柴胡三大优势守护冬季健康
- 从国标到新国标 伊利金领冠实力领航行业“进阶”路
- 8大赋能9大服务 韩甜控股带领瘦身行业“弯道超车”
- 哇牛养车,让车辆养护变得更简单
- 和府捞面:新时代养生普惠,打造“超级质价比”
- “亦创未来”北京经开区短视频大赛正式启动
- 云仓酒庄:多品牌运营方的策略与路径
- 焕“芯”升级 发现精彩 广发银行发现精彩app接入银联云闪付网络支付平台
- 辉山奶粉&爱奇艺《一念关山》热剧营销释放品牌势能
- 长虹空调:“10年包修”政策发布,精工品质 创新产品抢滩行业新风口!
- 粉&爱奇艺《一念关山》热剧营销释放品牌势能
金融
财经
要闻
公司
一系列金融支持民营经济、民营企业发展的政策举措正密集出台加速落地。
9月份以来,人民币汇率持续走低。9月8日,离岸人民币对美元汇率盘中最
国家统计局发布的数据显示,8月份,全国居民消费价格指数(cpi)同比上
国家统计局9月9日发布的数据显示,8月全国居民消费价格指数(cpi)同比
今年前8个月,郑州商品交易所累计成交量约25亿手,同比增长64%。这是记
中国电影观众满意度调查2023年暑期档调查结果显示,暑期档电影观众满意